
概述
Q: 数据持久化是什么?
A: 数据持久化简单的说就是将APP生成、接收到的数据从内存上写入到硬盘、U盘等外部永久性存储设备上,以便应用重启后能继续使用这些数据。
Q: 数据持久化的作用以及常用的形式是什么?
A: 由于APP运行在内存中,这种存储器在断电时将丢失其存储的内容。数据持久化通常将内存中的数据以文件,数据库的形式写入到硬盘等断电不丢失数据的存储设备上,这样在应用重启后能够读到持久化也就是断电前的数据,以及恢复软件的状态,继续之前的工作。
Q: iOS中常用的数据持久化方式有哪些?
A:
preference
NSKeyedArchiver
FMDB(SQLite 3)
CoreData
MainBundle & 沙盒
在了解各种持久化方式前,我们先简单了解下iOS应用的MainBundle以及沙盒目录相关信息以及结构。
MainBundle(安装目录)
MainBundle是指APP在手机中的安装路径,该目录下存放有关该应用的资源文件、可执行的二进制文件以及nib文件等程序运行所依赖的资源。
查看MainBundle目录:
通过更改应用后缀名.ipa到.zip,解压后显示包内容即可查看。
开发中获取MainBundle:
沙盒(数据目录)
沙盒机制
沙盒机制是苹果提供的访问控制技术。每个应用都有自己的沙盒,可以在对应的沙盒中进行读取和写入数据等操作,不能访问其他应用的沙盒的数据,可以说沙盒机制使得iOS系统更加安全。下图右侧为沙盒机制图解: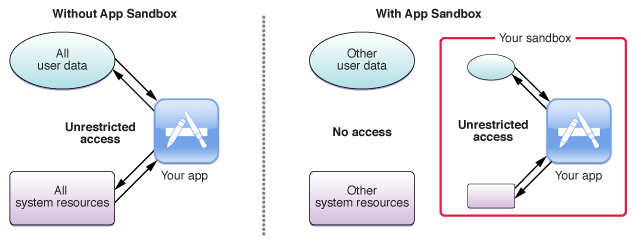
沙盒目录
|
|
进入到沙盒根目录后结构如下:
Document:
获取方法:NSDocumentDirectory
Document目录一般存储比较重要的文件例如:本地数据库、归档,应用信息等。通过 iTunes、iCloud 备份时会备份该目录下文件。
Library/Caches
获取方法:NSCachesDirectory
Caches目录一般存储体积较大不需要备份的文件例如:图片、音乐、视频缓存等。进行iTunes、iCloud备份时不会备份该目录下的文件,该目录下的文件不会被应用自动删除,需要程序提供清除缓存的方法去删除这些缓存数据。
Library/Preferences
Preferences目录存储有关应用偏好设置等重要信息,由系统的NSUserDefaults进行读写操作。进行iTunes、iCloud备份时会备份该目录下文件。
tmp
获取方法:
tmp目录一般存储应用产生的临时数据,该目录下的文件可能随时被系统清理掉,进行iTunes、iCloud备份时不会备份该目录的文件。
经过上面各个沙盒目录基本特点介绍后,我们在项目中可以根据不同的数据类型以及使用的场景选择恰当的存储目录进行数据持久化存储。下面我们进入正题~
preference
使用偏好进行数据持久化的实质是在Library/Preferences目录下生成一个以Bundle Identifier命名的.plist文件。并不是每种类型都能写入到plist文件中,plist文件接受NSNumber,NSString,NSDate,NSArray,NSDictionary,BOOL,NSData,Integer,float,double类型的数据。下面我们来看下它的基本用法:
写入:
读取:
偏好文件是由一个NSUserDefaults类型的单例来控制存储和读取的,而写入的synchronize方法不是一定调用的,因为系统默认也会调用,可能不是你想要的时间点。主动调用synchronize方法会立即执行写入操作是没有问题的。
注意点:
- plist默认支持以上的几种数据类型,如果我要想存储图片信息不能直接传入UIImage的类型,但可以将UIImage转换为NSData后进行存储。
- NSArray,NSDictionary中存储的对象也要是上面的这几种类型才能正确写入和读取。
- plist支持存储
NSMutableString,NSMutableDictionary,NSMutableArray这些可变的类型,但是再次读取出来的类型变为不可变类型的。官方给的介绍如下:Values returned from NSUser Defaults are immutable, even if you set a mutable object as the value. For example, if you set a mutable string as the value for "My String Default", the string you later retrieve using string For Key: will be immutable.
以上是对preference存储的简单介绍,更多关于偏好存储的信息可以查阅官方文档Apple Document
NSKeyedArchiver
除了使用偏好设置plist进行简单的存储外,iOS还提供了另外一种持久化方式归档。这种方式的存储一般存储某个类实例的数据以便下次、以后使用。简单的来看这种存储方式就是将实例数据进行编码为二进制文件,然后用的时候再以归档时的规则进行解码的过程。
上代码之前我们先了解下归档 & 解档相关类和方法:
归档:NSKeyedArchiver继承自NSCoder,提供了工厂方法archiveRootObject:toFile:将对象写入指定文件路径。
解档:NSKeyedUnarchiver也是继承自NSCoder,提供的工厂方法unarchiveObjectWithFile:将对象从指定文件路径读出。
NSCoding协议:使用这种存储方式需要自定义对象实现NSCoding的两个方法:
|
|
归档方法:
解档方法:
既然Person已经提供了归档和解档的方法,我们就来看看如何使用吧:
归档
解档
以上是对Person对象归档以及解档的演示,其中主要的核心是将要进行归档的对象实现NSCoding协议。再调用对应的归档方法[NSKeyedArchiver archiveRootObject:person toFile:filePath],以及解档方法[NSKeyedUnarchiver unarchiveObjectWithFile:filePath]去实现对象数据的存储和读取。其实在调用上述的归档方法、解档方法的背后调用了Person实现的归档和解档方法。
注意点:
- 使用这种存储方式的前提是要遵守NSCoding协议并实现两个解、归档的方法。
- 归档这种存储方式不能够单独的对一个对象的某一个属性设置值,归档操作是一种覆盖操作,需要写入整个对象进行数据更新。所以这样的存储方式不适合那种经常对某一个属性进行更改的场景。
- 如果对象的父类也实现了
NSCoding协议,在initWithCoder:方法中需要调用[super initWithCoder:]来进行初始化。
以上是对归档的这种方式持久化的介绍,想要获取更多有关归档的信息可以参考苹果官方文档Apple Document
FMDB(SQLite 3)
除了上面的两种持久化方式之外还有个非常便利、轻巧的持久化存储方式–数据库。在这里简单介绍下SQLite 3,SQLite是一种轻型的关系型数据库,提供了大部分的数据库基础操作增、删、改,查。由于SQLite提供的都是C语言的API,不易使用和理解。所以我们在开发中使用封装了SQLite 3 的FMDB这个第三方库进行数据库的管理。
FMDB简介
在使用FMDB之前我们先简单了解FMDB相关的核心类和方法:
FMDatabase
提供了数据库的各种操作(打开关闭数据库,增删改查等)12// 更新数据库API- (BOOL)executeUpdate:(NSString*)sql;12// 查询数据API- (FMResultSet *)executeQuery:(NSString*)sql;
FMResultSet
数据库执行查询语句的结果集(每一行的数据集合)12// 获取数据库上对应字段的字符串- (NSString*)stringForColumn:(NSString*)columnName12// 获取数据库上对应字段的int数据- (int)intForColumn:(NSString*)columnName
- FMDatabaseQueue
提供多线程数据库操作下的线程安全。
FMDB的使用
下面演示的FMDB的使用主要包括数据库文件的创建、创建表、以及数据库的基本操作增、删、改、查、事务,线程安全等的使用。该演示代码被封装在一个数据库管理工具DataBaseTool中,读者可以根据自己的设计思路对数据库的功能代码进行封装。
创建数据库文件
在本例中所有的数据都是程序所产生的,所以数据库文件的创建放到了代码中,而不是将创建好的数据库文件放到bundle中。如果程序有依赖的数据库数据,比如一个不会更新的城市列表,一个程序所需要的数据字典,这种情况可以将数据库文件放到bundle中,待程序第一次使用时将数据库文件移动到沙盒文件目录下面使用。下面是本示例中的数据库文件创建:
上面是获取数据库文件的路径,如果获取路径上没有对应的数据库文件将会创建一个空的数据库文件。然后结合下面的两个方法+ (BOOL)openDB;,+ (BOOL)closeDB;操作数据库的打开和关闭:
每个操作数据库功能方法都需要打开和关闭数据库,因此我们提供的方法类似下面这样:
创建表
创建好对应的数据库文件,我们就可以在对应的数据库文件中创建表了。一般而言一个应用对应一个数据库即可,不同的模块、业务可以有自己的一个或者多个表,下面是创建person表的代码块:
创建表的sql语句:CREATE TABLE IF NOT EXISTS tableName(字段1 类型 字段约束, 字段2 类型 字段约束,..)
使用上面的这个方法我们就创建了一个t_person的表,其字段结构如下: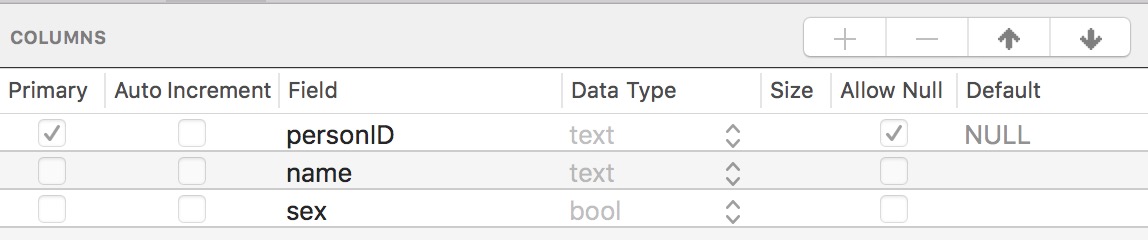
增
既然表已经创建好了那我们就给它添加点数据吧!
添加数据的sql语句:INSERT INTO tableName (字段1,字段2,...) VALUES ('value1','value2',...)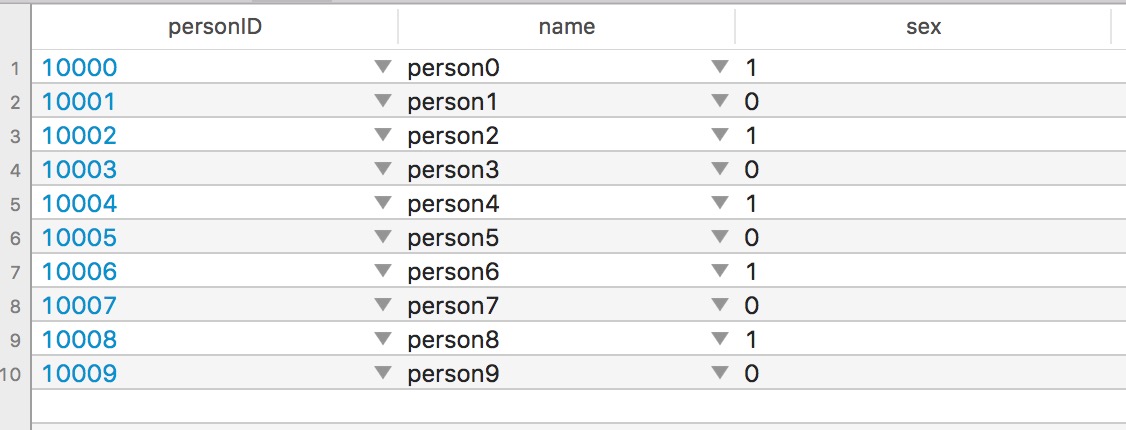
删
如下代码是删除personID为10000的操作:
删除数据的sql语句:DELETE FROM tableName WHERE express,当没有条件语句则删除表中所有数据。
改
下面是将personID为10001时的name和sex分别更改为superMan、1:
更新数据的sql语句:UPDATE tableName SET 字段1='值1',字段2=‘值2’ WHERE 字段=值。
查
现在查询sex为1的所有数据:
查询数据的sql语句:SELECT * FROM tableName WHERE 字段=值这种是最简单的选择语句,有时你可能还需要限定很多条件总的样式如:SELECT-FROM-WHERE-GROUP BY-HAVING-ORDER BY
事务
先简单描述下事务,开始一个事务->一个数据库操作->提交事务这就是一个事务的过程,其中伴随着IO的操作。如果将上面的事务执行10000次就会有10000次的IO操作这样肯定影响数据的执行效率,所以我们可以将一个数据库操作改成多个数据库操作,这样来避免多次IO操作提高数据执行效率。除了这个事务可以保证数据一致性,多个数据库操作如果其中一个操作出现异常可以将数据回滚到初始状态,一般用在绑定的事件上。比如A向B转账,A花钱,B收钱其中任何一个环节出现问题都需要回滚数据。下面先看下不用事务处理,执行10000次的插入操作:
我们看下日志打印的时间startExecute:19:11:51.126,endExecute:19:12:03.098,开始执行到结束执行一共用了大概12秒的样子,这个我是在模拟器上跑的时间真机上会比这个时间更长。
下面是使用事务的代码:
再来看下执行的开始和结束的打印时间startExecute:19:23:02.551,endExecute:19:23:02.652仅仅相差100毫秒,跟不使用事务有着明显的差距。还有,上面的代码演示了两个任务A&B如何利用事务的一致性进行数据回滚!好了使用事务带来的效率提升你已经看到了,以后涉及到大量数据操作时别忘了使用事务来处理~
线程安全
当数据库操作是在多线程下操作时使用同一个FMDatabase实例是会出现问题的,那么如何避免这种问题,让多线程下的数据库操作变得安全呢,就是使用FMDatabaseQueue这个核心类,一般应将FMDatabaseQueue的实例作为静态变量存储,它的实例化通过一个APIdatabaseQueueWithPath:使用数据库路径创建。
|
|
|
|
上面是模拟了,多线程下的数据库操作,如果没有使用FMDatabaseQueue执行过程因多个线程共同争取同一资源而出现crash。好了,至此FMDB的相关知识大多都了解到了,还有兴趣深入研究学习的请查看源码或各大搜索引擎查找资料。
注意点:
- 项目中需要导入FMDB第三方框架,并且在项目target中导入libsqlite3的动态库。
- FMDB对改动数据库的操作都叫做更新使用
executeUpdate这个API,对应选择查询语句的使用executeQuery这个API。 - 在sql语句中可以用
?来代替一些变量比如%@、%d的占位符。 - 多线程操作下要对每个数据库采取线程安全操作即使用
FMDatabaseQueue。