双链表简介
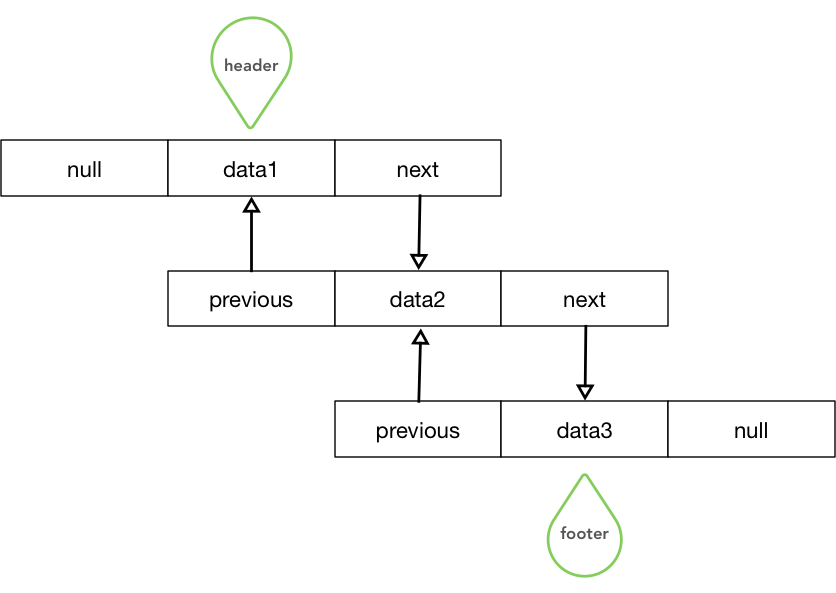
双链表的结构如上,跟单链表相比只是增加了结点的向前引用,下面简单过一下相关双链表的构成元素:
结点:构成双链表的基本单元,每个结点都有一个data区和两个结点指向区。data区就是存放数据的地方,一般存储基本类型数据或者引用对象的地址,两个结点previous,next分别指向前一个结点地址和下一个结点的地址。
头结点:首结点,指向双链表中的第一个结点。
尾结点:指向双链表中的最后一个结点。
链表长度:记录链表中存在的结点个数,即我们存储的数据个数。
双链表的实现
双链表相比单链表只是增加了向前结点的引用构成双向结构,整体来看跟单链表保持一致。双链表的优势体现在获取某个结点的前一个结点提供了便利。建议在了解双链表之前先看下单链表的基本实现,以便自己区分两者的细微区别。由于双链表和单链表结构保持一致,该博客主要流程仍然使用java语言进行讲解。
结点类的创建
创建链表的基本单元结点类跟单链表结点类相差不大,该类提供了数据存储区和前后接点指向区,以及便捷的构造函数:
双链表类的创建
跟单链表一样该模块实现数据的添加、删除、打印,反转等功能,下面是DoubleLinkedList的主要成员变量的介绍:
添加功能
添加方法分为了两种,一种是直接在链表尾部添加一个数据,另一个是在指定位置结点的后面添加一个数据。
相比于单链表private void addElement(Node<E> frontElement,Node<E> element)这个核心处理方法有点变化,就是要将previous的更改处理好。主要体现在:
删除功能
删除功能也提供了两种方式:一个将index所在的数据删除,另一种是将对象地址相同的对象删除。代码如下请自行对比与单链表的不同处理:
链表的反转
链表的反转即将链表原有的数据顺序以及指向颠倒下,请先看源码实现:
双链表的反转有别于单链表的递归实现而是通过循环遍历各个节点,对每个节点的previous和next进行互换,最后再对header和footer进行互换就可以达到我们想要的效果。
其它的方法
这里展示双链表其它相关方法如下:
总结
双向链表跟单链表一样具有相同的优点:结点的添加(插入)、删除比较方便,不需要占用较大的连续存储空间,除此之外双向链表表现的更为灵活。当然查询操作效率比较低下。
附加
更多相关内容请前往内功修炼系列!!!
|
|